

Gemini 1.5 acaba de ser lanzado y con él viene una vista previa de Gemini 1.5 Pro. Gemini Pro es el modelo que impulsa la versión gratuita de Gemini, lo que significa que los consumidores habituales podrán usarlo gratis muy pronto. Si estás emocionado por lo que eso significa, tenemos una lista de todas las cosas que Google dice que Gemini 1.5 Pro puede hacer y que Gemini 1.0 no podía.

Gemini 1.5 tiene mejoras masivas, pero aún no está disponible para todos
Gemini 1.5 ya está aquí y llegará primero al modelo Pro. Los desarrolladores y usuarios empresariales pueden usarlo ahora.
1Gemini 1.5 tiene una ventana de contexto significativamente más grande
Una ventana de contexto es lo que un LLM puede "ver"
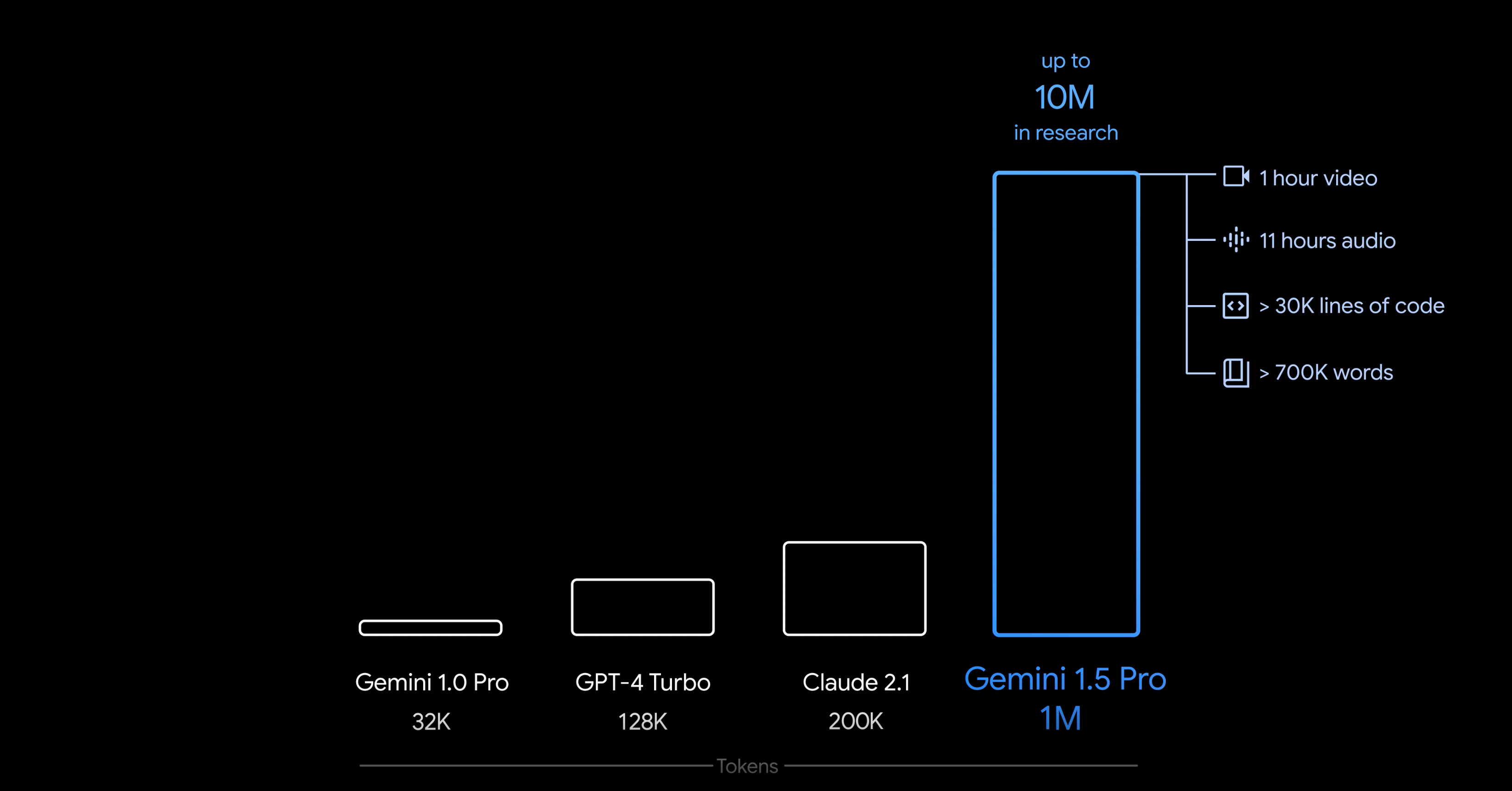
Gemini 1.5 tiene una ventana de contexto que llega hasta los 10 millones de tokens en investigación, y tendrá hasta 1 millón de tokens para los consumidores habituales. Esa ventana de contexto más grande costará dinero, pero la versión gratuita de Gemini 1.5 Pro seguirá teniendo una ventana de contexto de 128K. Como referencia, GPT-4 Turbo también tiene una ventana de contexto de 128K, y tanto Gemini Proahoracomo GPT-4 normal tienen una ventana de contexto de 32K. 1 millón de tokens es una novedad en la industria.
Las ventanas de contexto en la inteligencia artificial funcionan como la memoria colectiva que influye en el procesamiento de la IA. Encapsulan todos los datos necesarios para que la IA comprenda una consulta y formule una respuesta. Esto incluye la solicitud inicial del usuario, junto con cualquier contexto complementario o interacciones anteriores. La amplitud de la ventana de contexto desempeña un papel crucial a la hora de determinar la cantidad de información que el modelo puede retener de partes anteriores de la conversación o el texto, lo que afecta directamente a su capacidad de ofrecer respuestas coherentes y pertinentes.
El beneficio que esto le reporta al usuario depende completamente de cómo utilice un LLM. Si solo desea hacer preguntas básicas y no hacer mucho más, no obtendrá ningún beneficio. Si utiliza un LLM para codificar u otras cosas que pueden requerir respuestas más largas, una ventana de contexto más grande puede resultarle muy beneficiosa. Google dice que se esperan latencias más altas en ventanas de contexto más altas, pero eso es algo que se espera actualmente.
2Gemini 1.5 Pro es mejor en codificación que Gemini 1.0Ultra
Obviamente también fuma Gemini 1.0 Pro
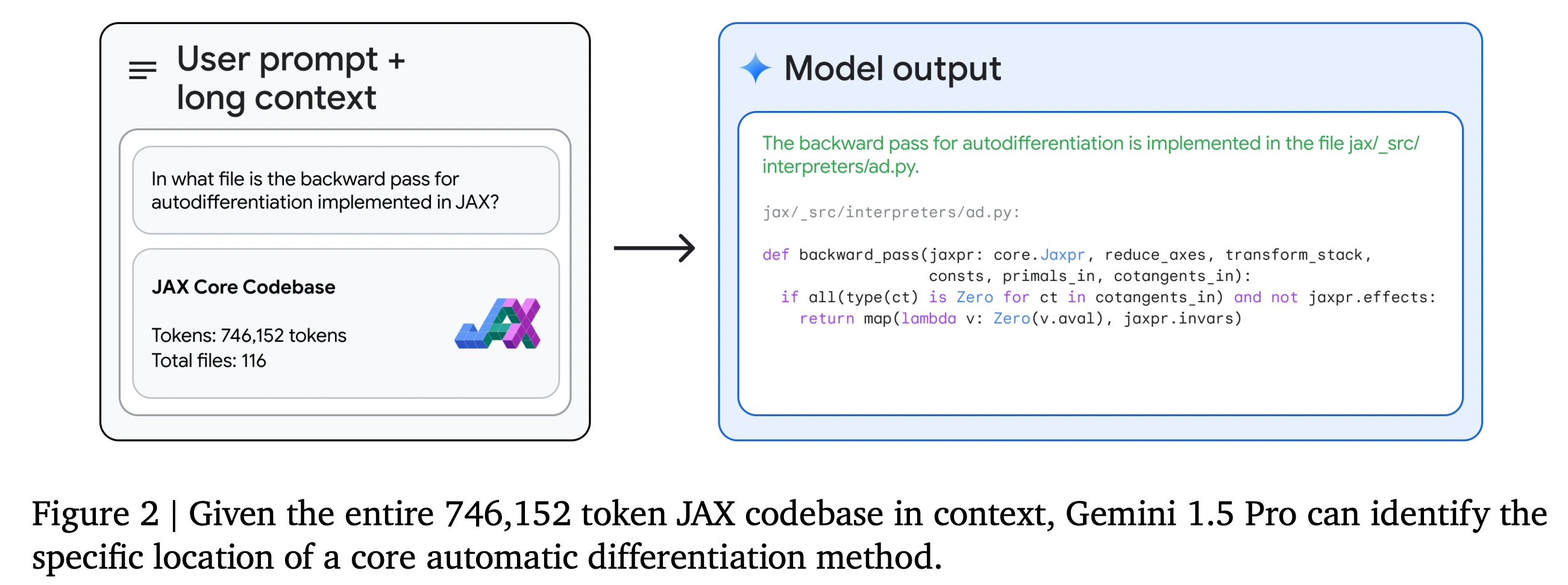
Si utilizas LLM para codificar, te alegrará saber que Gemini 1.5 Pro hace un trabajo de codificación incluso mejor que Gemini 1.0Ultra, y más aún que Gemini 1.5 Pro. Eso es segúnel documento técnico de Google, que dice lo siguiente.
Gemini 1.5 Pro es nuestro modelo con mejor rendimiento en código hasta la fecha, superando a Gemini 1.0 Ultra en Natural2Code, nuestro conjunto de pruebas de generación de código interno creado para evitar fugas de la web.
Para cualquiera que utilice LLM para programar, esto es muy importante. Gemini Advanced es bueno para programar, pero siempre puede ser mejor, y sigo prefiriendo ChatGPT Plus para cualquier cosa relacionada con la programación que haga. Si es mejor para programar que el modelo Ultra, entonces eso es un gran augurio para cualquiera que lo use para programar normalmente.
3Puede analizar cantidades significativas de datos.
Eso incluye 100.000 líneas de código, según Google.
Como consecuencia de esa ventana de contexto más grande, Gemini 1.5 Pro puede comprendermásde lo que le proporciones. Si bien esto se supone dado que la ventana de contexto aumenta, no hay garantía de que el LLM sea capaz de responder con el mismo nivel de calidad a entradas más grandes que a entradas más pequeñas. Google ha asegurado a las personas que es tan capaz de responder a entradas más grandes como a entradas más cortas, demostrándolo al pedirle ayuda a Gemini con un programa que abarca más de 100.000 líneas de código.
Con esto, Google afirma que puede realizar modificaciones, sugerencias y ayuda de manera razonable a grandes cantidades de información a la vez, ya que el código base mencionado anteriormente utiliza más de 800 000 tokens. Se trata de una cantidad absurda de tokens y es más de lo que cualquier otro LLM puede lograr actualmente. Para ello, Google también le proporcionó una película muda de 44 minutos, en la que le preguntó a la IA sobre detalles específicos de la película. Pudo responder con respuestas correctas.
Gemini 1.5 Pro extiende significativamente esta frontera de longitud de contexto a varios millones de tokens sin prácticamente ninguna degradación del rendimiento, lo que hace posible procesar entradas significativamente más grandes. En comparación con Claude 2.1 con una ventana de contexto de 200 000 tokens, Gemini 1.5 Pro logra una recuperación del 100 % con 200 000 tokens, superando el 98 % de Claude 2.1. Esta recuperación del 100 % se mantiene hasta 530 000 tokens, y la recuperación es del 99,7 % con 1 millón de tokens. Al aumentar de 1 millón de tokens a 10 millones de tokens, el modelo conserva una recuperación del 99,2 %.
Además, Google también le proporcionó la transcripción completa de 402 páginas del control tierra-aire con el Apolo 11, y podría hacer lo mismo también. Poder analizar una gran cantidad de datos es una gran ventaja a favor de Google y ayudará a las personas que manejan grandes bases de código o rastrean cantidades considerables de datos.
Google explicó cómo utilizó una evaluación de tipo "aguja en un pajar", en la que se oculta un pequeño fragmento de texto que contiene un hecho o una afirmación en particular dentro de un bloque de texto largo. Gemini 1.5 Pro lo encontró el 99 % de las veces, incluso en bloques de datos que llenaban la ventana de contexto de 1 millón de caracteres.
4Se puede aprender en una conversación.
Los investigadores le enseñaron kalamang, una lengua hablada por menos de 200 personas.
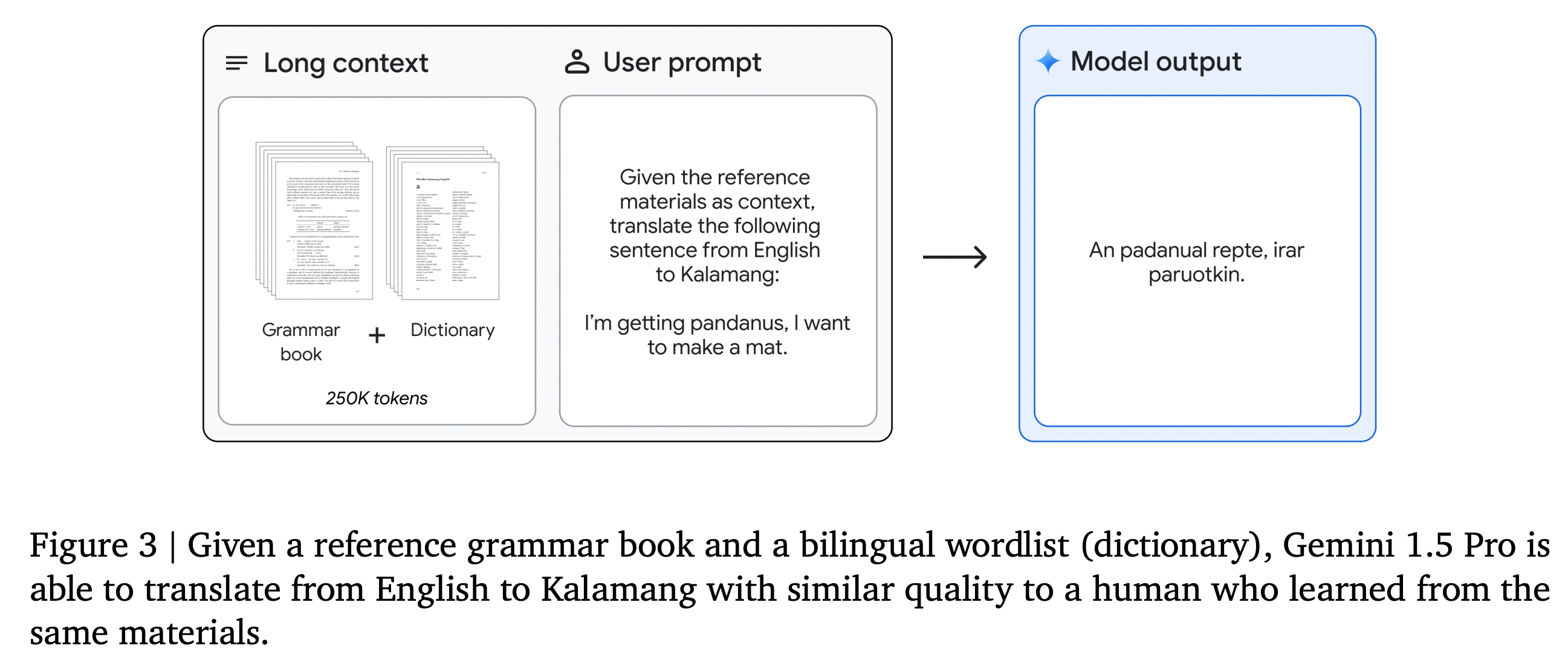
Los LLM no son capaces de todo, especialmente si no fueron entrenados con datos que parecen representar una respuesta a una pregunta. Por eso, para los idiomas pequeños, los LLM no son tan poderosos. Puedes intentar enseñarle un idioma a un LLM, pero lo más probable es que llenes su ventana de contexto o que no pueda adaptarse. Los investigadores de Google enseñaron a Gemini 1.5 Pro Kalamang dándole un manual de gramática, un idioma con menos de 200 hablantes en todo el mundo. Dijeron que el modelo era capaz de "traducir del inglés al kalamang a un nivel similar al de una persona que está aprendiendo el mismo contenido".
Si bien no es perfecto, esto significa que el LLM de Google podrá asimilar más información que usted le proporcione y que posiblemente no conocía previamente y aplicarla al resto de la conversación.
5Debería responder más rápido
Esto es gracias a la arquitectura Mixture-of-Experts.
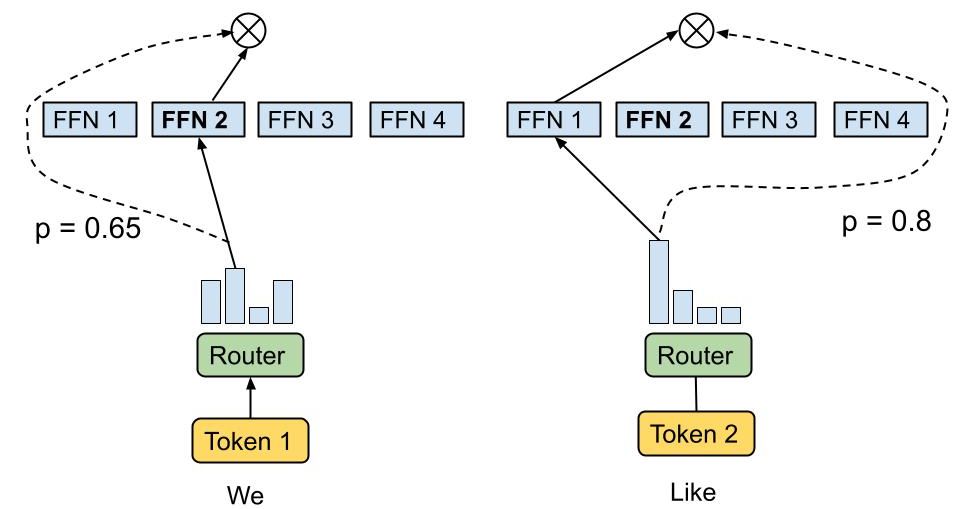
Los LLM que incorporan una arquitectura de mezcla de expertos (MoE) procesan la información mediante el enrutamiento de tokens a redes neuronales especializadas dentro del sistema, elegidas por su relevancia para la tarea en cuestión. Esta arquitectura permite un enfoque dinámico y eficiente para responder consultas, con el potencial de una estructuración jerárquica donde una red de expertos podría ser en sí misma un MoE. El proceso de selección implica una red de enrutamiento que identifica al experto o expertos más adecuados para cada token, lo que da como resultado una respuesta generada a partir de la experiencia combinada de múltiples redes neuronales. Gemini ahora utiliza una arquitectura MoE, que debería dar como resultado respuestas más rápidas.
La arquitectura MoE mejora la eficiencia computacional, lo que resulta particularmente beneficioso durante la fase de entrenamiento inicial del modelo, aunque puede provocar un sobreajuste durante el ajuste fino, en el que el modelo memoriza y replica en exceso los datos de entrenamiento. Además, los MoE pueden ofrecer tiempos de inferencia más rápidos al activar solo un subconjunto relevante de expertos para cada consulta, lo que optimiza el uso de recursos. Sin embargo, dar soporte a modelos tan sofisticados requiere recursos de memoria considerables, ya que su gran cantidad de parámetros, a menudo de miles de millones, requiere una cantidad sustancial de RAM para un funcionamiento eficaz.
Si bien no está claro exactamente cómo esto beneficiará a Gemini, debería poder hacer inferencias mucho más rápido que su predecesor. Mixtral 8x7B es uno de esos LLM que ha incorporado MoE con gran éxito, creando un modelo con la potencia de un modelo 47B mientras que solo requiere las capacidades necesarias para ejecutar un modelo 12.9B. Hay grandes ganancias que se pueden obtener aquí tanto en rendimiento como en ahorro de costos para Google, por lo que sospecho que lo están usando.
Gemini 1.5 es un gran paso para Google
La mejora más importante aquí es, sin duda, la ventana de contexto más grande, ya que permite muchas de estas mejoras. Google incluso dice que Gemini 1.5 Pro supera a Gemini 1.0 Ultra en muchos escenarios diferentes, "a pesar de que Gemini 1.5 Pro utiliza significativamente menos computación de entrenamiento y es más eficiente para servir". Hay mucho de qué entusiasmarse aquí, especialmente si eres un defensor de los LLM o alguien a quien le entusiasma el desarrollo de la IA en general.
Aún no está del todo claro cuándo llegarán estos cambios a los consumidores, ya que los desarrolladores ya pueden empezar a utilizar Gemini 1.5 Pro hoy mismo. También se espera que Gemini 1.5 Ultra esté en camino, aunque Google no ha mencionado nada al respecto todavía. Aun así, está claro que Google quiere ser el mejor actor en materia de inteligencia artificial en este ámbito.

Google Gemini Advanced vs ChatGPT Plus: ¿cuál es mejor?
Ambos servicios son excelentes y cuestan lo mismo, pero ¿cuál es mejor: Gemini Advanced o ChatGPT Plus?