

ComfyUI es una interfaz gráfica de usuario de Gradio basada en nodos diseñada para modelos de IA generativos. Es una de las formas más versátiles de generar imágenes, videos y audio de IA de forma local en su propio hardware. Sin censura de software ni requisitos de suscripción, ofrece miles de nodos y modelos de IA con un control de usuario excepcional. ComfyUI es una herramienta increíblemente poderosa para cualquiera que desee mantenerse a la vanguardia de la IA.
Es un mito que necesites tener una GPU increíblemente potente o ser programador, como algunos pueden creer, aunque esas cosas aceleran el proceso. Puedes ejecutar muchos modelos de generación de imágenes con entre6 GB y 8 GB de VRAMen una buena computadora portátil. ComfyUI y otras opciones de GUI como Automatic1111 o InvokeAI pueden tener una curva de aprendizaje significativa, pero no son más desafiantes que aprender a usar Adobe Photoshop.

Estas son las mejores alternativas a Adobe Photoshop que he usado gratis
¡Adiós, suscripción a Creative Cloud!
Lo que necesitas para empezar
La configuración manual de ComfyUIrequiere algunos conocimientos técnicos y familiaridad con Python. La aplicación de escritorio ComfyUI V1, ahora enversión beta cerrada, promete simplificar el proceso de configuración. Hasta su lanzamiento, puedes usar lacomputadora virtual Pinokiopara una instalación sencilla de ComfyUI si no quieres complicarte con comandos de terminal y entornos virtuales de Python.
Esta guía no pretende ser un simple tutorial para principiantes, sino que proporciona los conocimientos básicos necesarios para experimentar y aprender por su cuenta. Cada paso destaca las técnicas esenciales y conduce a un flujo de trabajo básico. El objetivo es ayudarle a comprender los elementos centrales de un flujo de trabajo sin la frustración de tener que descifrar el proceso complejo de otra persona.
Instalación de modelos de punto de control, LoRA, VAE y nodos personalizados
Primero, instale ComfyUI manualmente o con Pinokio visitando los recursos anteriores. Para fines de aprendizaje, esta guía utiliza un modelo Stable Diffusion 1.5 (SD 1.5) más antiguo, que tiene menores requisitos de VRAM y velocidades de generación más rápidas.
Civitaies un excelente recurso para descargar modelos, herramientas y flujos de trabajo. Puedes filtrar por las opciones mejor valoradas y ordenarlas para encontrar las más populares. Para comenzar, te sugiero que pruebesMeinaMix V12 - Finalpara anime yRealistic Vision V6.0 B1para fotorrealismo. En general, son fáciles de usar y producen resultados decentes de manera constante, incluso cuando se utilizan flujos de trabajo muy básicos.
Los modelos baseson modelos originales entrenados, como SD 1.5, SDXL, Pony o Flux. Considere quelos modelos de puntos de controlson como modelos base que se han refinado o fusionado con otros puntos de control para producir ciertos tipos de imágenes, siendo las más comunes las de anime y las fotorrealistas.
Civitai.com tiene mucho contenido no apto para el trabajo, mientras que Civitai.green ofrece una alternativa segura para el trabajo. Asegúrate de comprobar dos veces la URL que estás visitando.
En el futuro, utilizarásmodelos LoRA(adaptación de bajo rango) con frecuencia. Piensa en ellos como modelos más pequeños que realizan ajustes muy específicos al modelo de punto de control. Por ejemplo, puedes usar un LoRA estilo Studio Ghibli con MeinaMix para generar imágenes en ese estilo artístico. Sin embargo, los LoRA no se limitan al estilo, hay LoRA para personajes y personas específicos, prendas de vestir, poses, peinados, entornos, etc. Usaremos un LoRA simple destinado a aumentar la calidad para esta guía llamadaPerfection “SD1.5” v0.9.
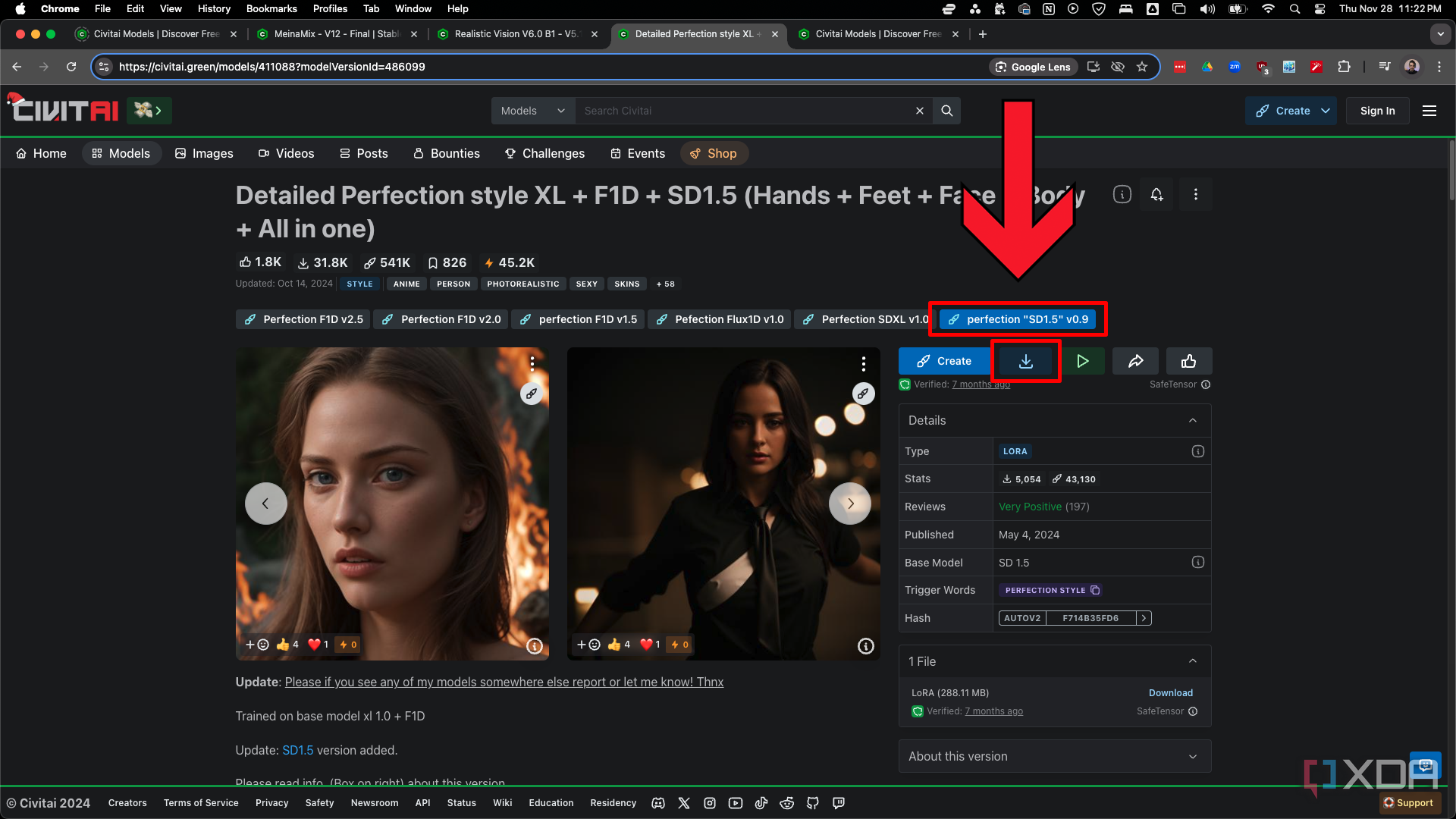
Inicie ComfyUI y haga clic en el botónAdministradoren la esquina superior derecha. Haga clic enAdministrador de nodos personalizados. Busque “chooser” y haga clic enInstalarparael ID n.° 241 Selector de imágenes. Haga clicen Cerrarpara volver al menú Administrador de ComfyUI y haga clic enAdministrador de modelos. Busque “vae” y haga clic enInstalarparael ID n.° 105 vae-ft-mse-840000-ema-pruned. Cierre el menú Administrador de ComfyUI para volver a la pantalla principal. Haga clic enActualizaren la parte superior de la pantalla si está usando Pinokio o simplemente actualice la página web si está usando un navegador web estándar.
El nodo personalizadoSelector de imágenesserá el único nodo no principal que usaremos. Pausa un flujo de trabajo después de que se genera una imagen, de modo que puede cancelar antes de guardar o algunos pasos importantes en flujos de trabajo más complejos. Elmodelo VAE(codificador automático variacional) suele estar "integrado" en la mayoría de los modelos de puntos de control, pero lo estamos instalando para que sepa cómo usar diferentes VAE en el futuro. Abordaremos qué es un VAE y qué hace en la siguiente sección.
Recomiendo encarecidamente el sitio webStable Diffusion Artsi te quedas atascado en algún paso. Los tutoriales están bien escritos y son fáciles de seguir.
Nodos centrales en un flujo de trabajo básico
Te sugiero que construyas los elementos básicos de un flujo de trabajo desde cero cada vez que comiences un nuevo proyecto, hasta que puedas hacerlo de memoria. Entender esta estructura básica te ayudará a solucionar problemas con los flujos de trabajo de otros cuando comiences a probarlos e inevitablemente te topes con problemas. ComfyUI y los nodos personalizados se actualizan con frecuencia, y es fácil que te encuentres con nodos faltantes en flujos de trabajo más antiguos.
Haga doble clicen cualquier lugar de la pantalla y busque un nodo por nombre para agregarlo al flujo de trabajo.
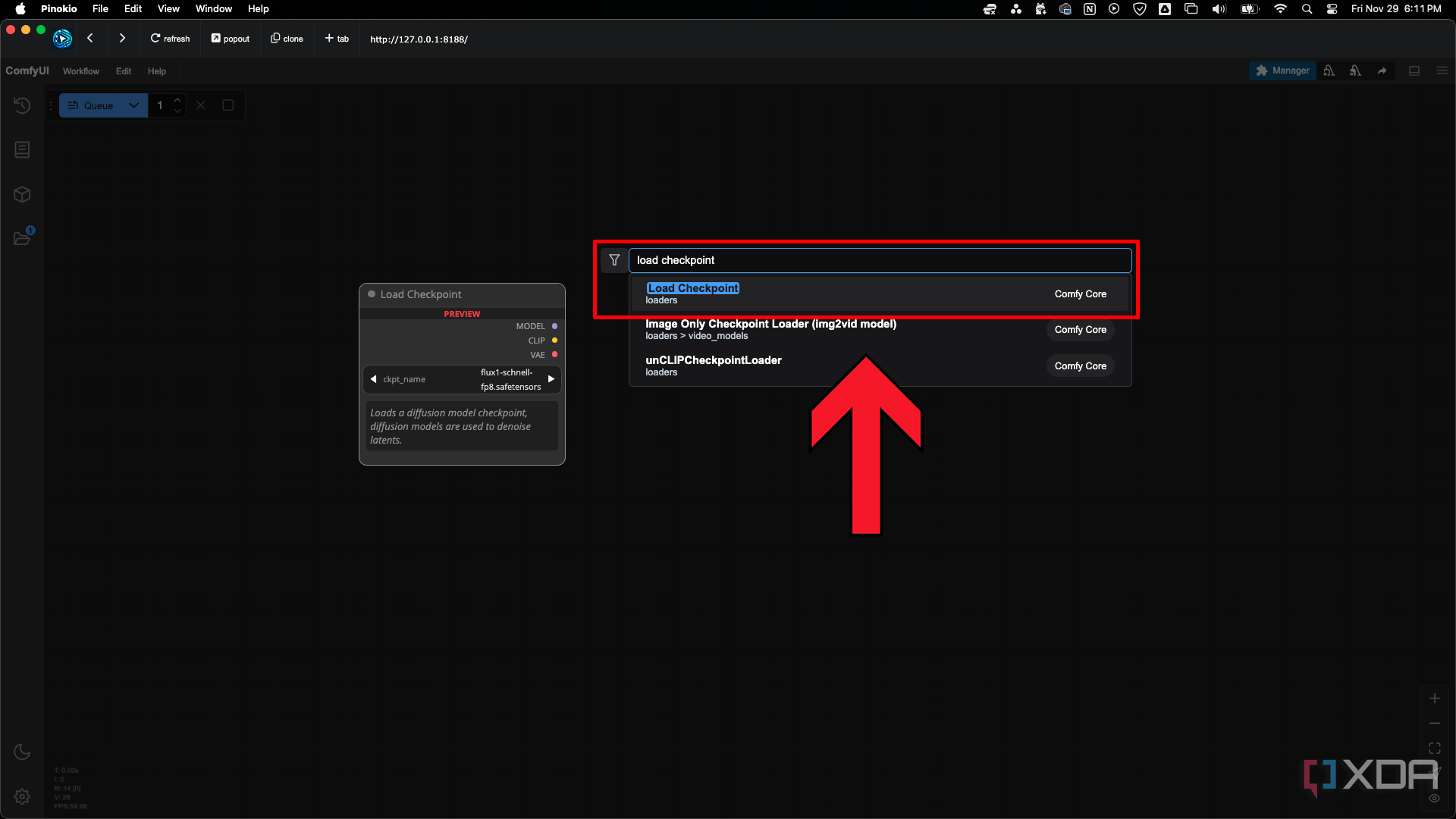
Comience con un nodode punto de control de carga, VAE de carga y imagen latente vacía. Haga clic en los campos de texto de los nodos para cargar los modelos descargados anteriormente. En la carpetacomfyUI hay una carpeta llamadamodels. Dentro de esa carpeta hay subcarpetas para colocar sus descargas que tienen el nombre correspondiente.
Cargar salidas del nodo Punto de control
Lasalida CLIP(preentrenamiento de imagen y lenguaje contrastante) del nodoLoad Checkpointse conectará con los nodos en los que ingrese su mensaje de texto. CLIP es otro modelo de IA que está integrado en el modelo de punto de control. Se lo entrenó para determinar qué tan bien se ajustan los subtítulos de texto a sus imágenes. Piense en él como un traductor que puede convertir su mensaje de lenguaje natural en un idioma que la IA comprenda.
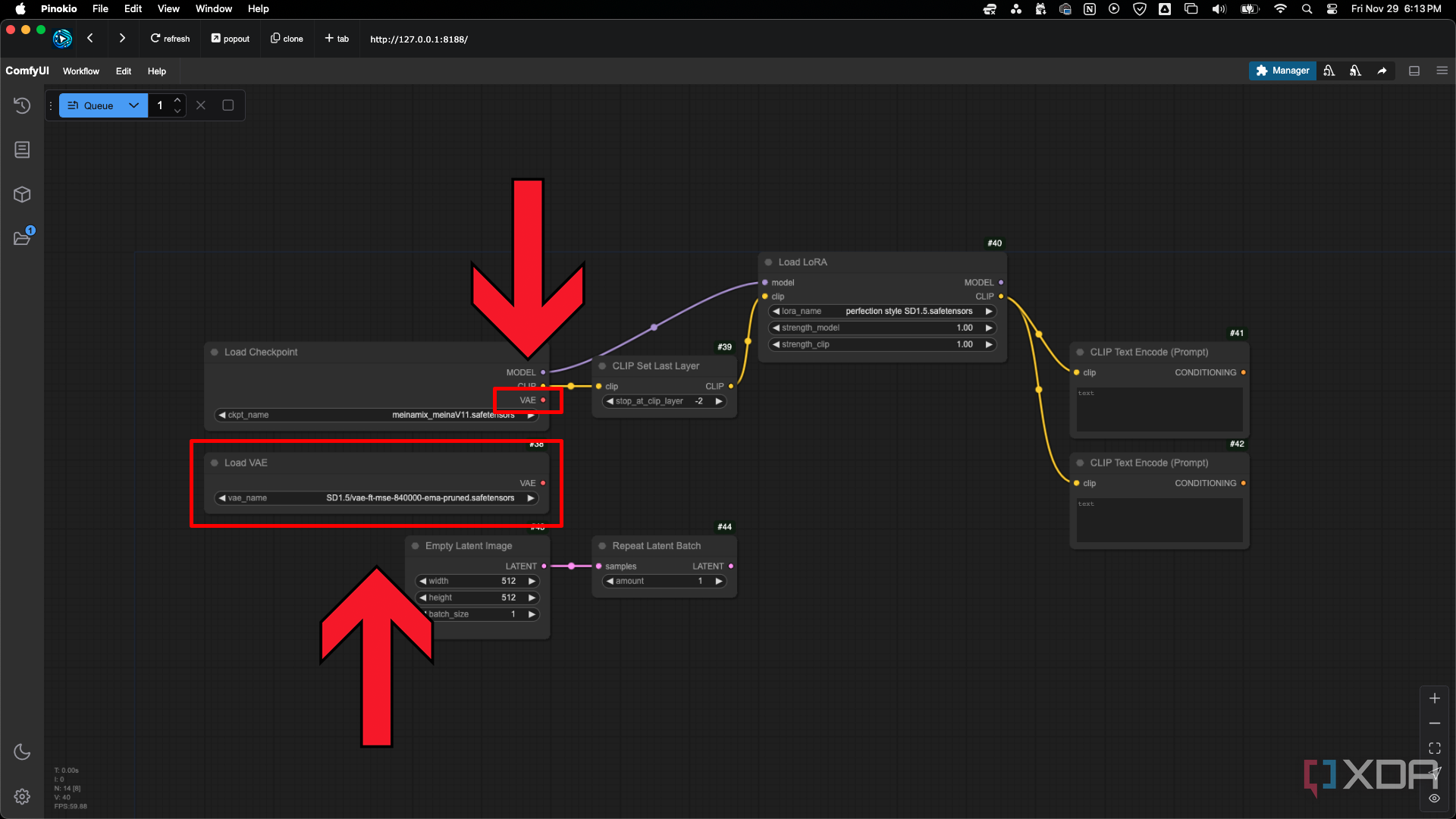
Cargar nodo VAE
Por lo general, utilizará lasalida VAEdel nodo Load Checkpoint. La VAE también está integrada en la mayoría de los puntos de control, pero puede utilizar el nodoLoad VAEsi desea anularlo y utilizar una VAE diferente o cuando un punto de control no tiene una VAE integrada. La VAE convierte (decodifica) las imágenes generadas en el espacio latente en las imágenes finales visibles. En un flujo de trabajo de imagen a imagen, la imagen de entrada se convierte (codifica) en una imagen latente mediante la VAE.
Nodo de imagen latente vacía
El nodoEmpty Latent Image (Imagen latente vacía) proporciona un "lienzo" vacío para la generación de imágenes. Definir el ancho y la altura de una imagen latente vacía es como establecer el tamaño de un lienzo, aunque las imágenes latentes no son simplemente una nueva página vacía en la que dibujar. Los modelos base y los puntos de control están entrenados para generar imágenes en tamaños específicos. Puede encontrar tamaños recomendados para un modelo base o usar nodos como las opciones derelación de aspecto de Comfyroll Studio (ID n.° 78)para seleccionar tamaños comunes. El parámetrobatch_sizeen este nodo determina cuántas imágenes se generarán.

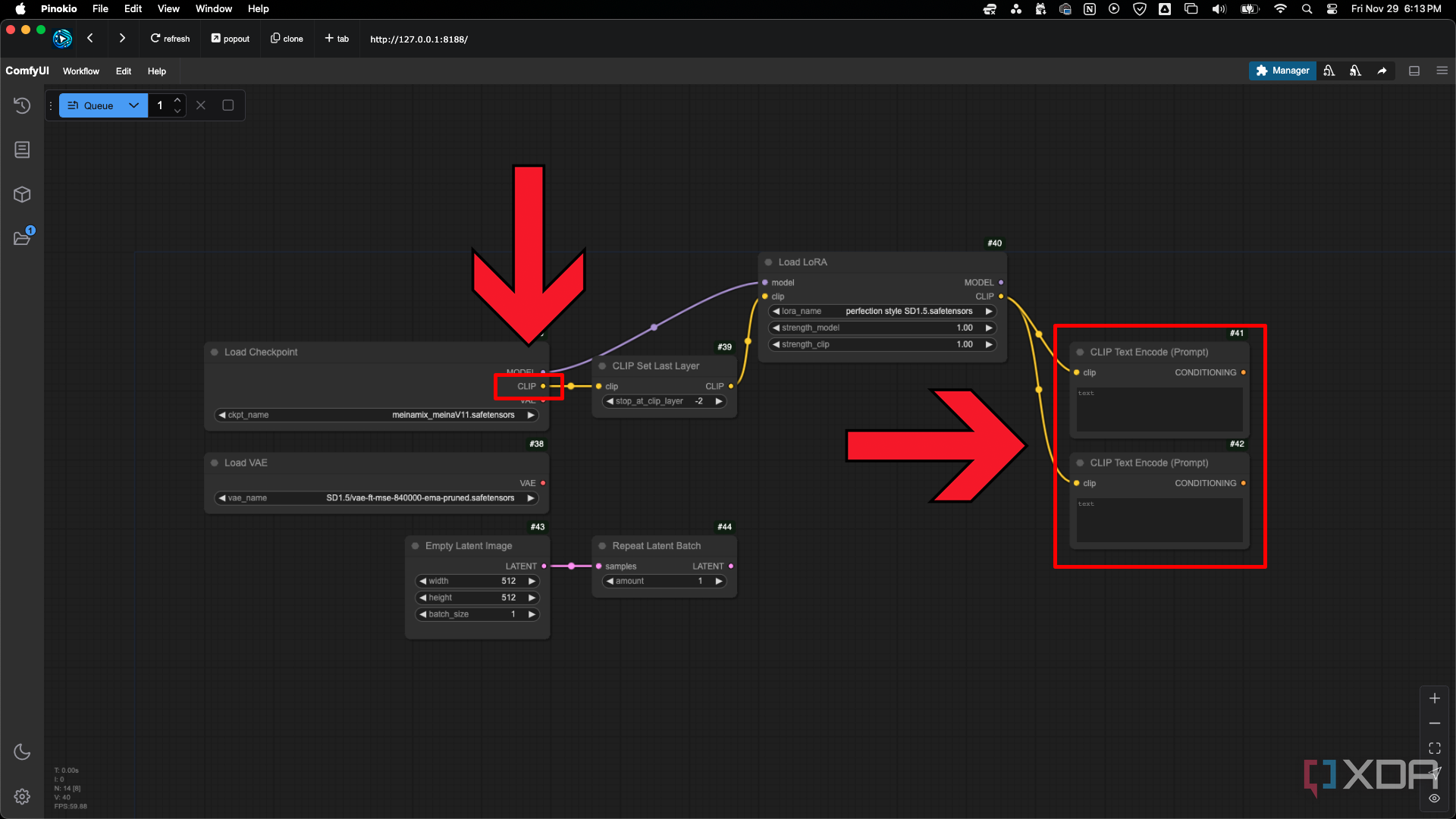
Agregue un nodoCLIP Set Last Layer, Repeat Latent Batch, Load LoRA y dosnodos CLIP Text Encode (Prompt) como se muestra en la imagen. No necesita los nodos CLIP Set Last Layer o Repeat Latent Batch en un flujo de trabajo simple, pero es probable que los use a medida que avanza.
Nodo de lote latente de repetición
Repetir lote latentees lo mismo que elparámetro batch_size, pero si en cambio estuviera convirtiendo una imagen en una latente para la generación de imagen a imagen, necesitaría una forma de establecer cuántas variaciones se deben generar al ejecutar el flujo de trabajo.
CLIP Establecer cambios en el nodo de la última capa CLIP Omitir
A menudo verás que se menciona "CLIP Skip" cuando se habla de Stable Diffusion. El parámetroCLIP Set Last Layercambia este parámetro. A veces, los puntos de control recomendarán una configuración de CLIP Skip, pero la mayoría de las veces no es necesario que la configures tú mismo. Este es un parámetro con el que es fácil experimentar y te animo a que lo pruebes. La configuración literalmente omite una capa en el proceso de generación, con -1 finalizando el proceso normalmente en la última capa, -2 finalizando en la penúltima capa, etc. Cada capa eliminada hace que la adherencia inmediata sea más generalizada.
Cargar nodo LoRA
Los parámetros del nodoLoad LoRAson simples. Te sugiero que no cambiesstrength_clipcuando estás empezando y que uses el parámetrostrength_modelpara ajustar cuánto afecta el LoRA a la imagen final. Los LoRA suelen tener rangos sugeridos que funcionan mejor, que puedes encontrar en sus descripciones en Civitai. Puedes conectar varios LoRA conectando sussalidasMODELy CLIP a las entradasmodelyclipde otro cargador LoRA. Por ejemplo, puedes usar un LoRA de un personaje de tu anime favorito en combinación con un estilo artístico en el que quieras ver representado a ese personaje.
Nodo de codificación de texto CLIP (aviso)
Los dos nodosde codificación de texto CLIP (aviso)se utilizan para sus avisos positivos y negativos, donde le dice a la IA lo que desea ver o no ver en la imagen.
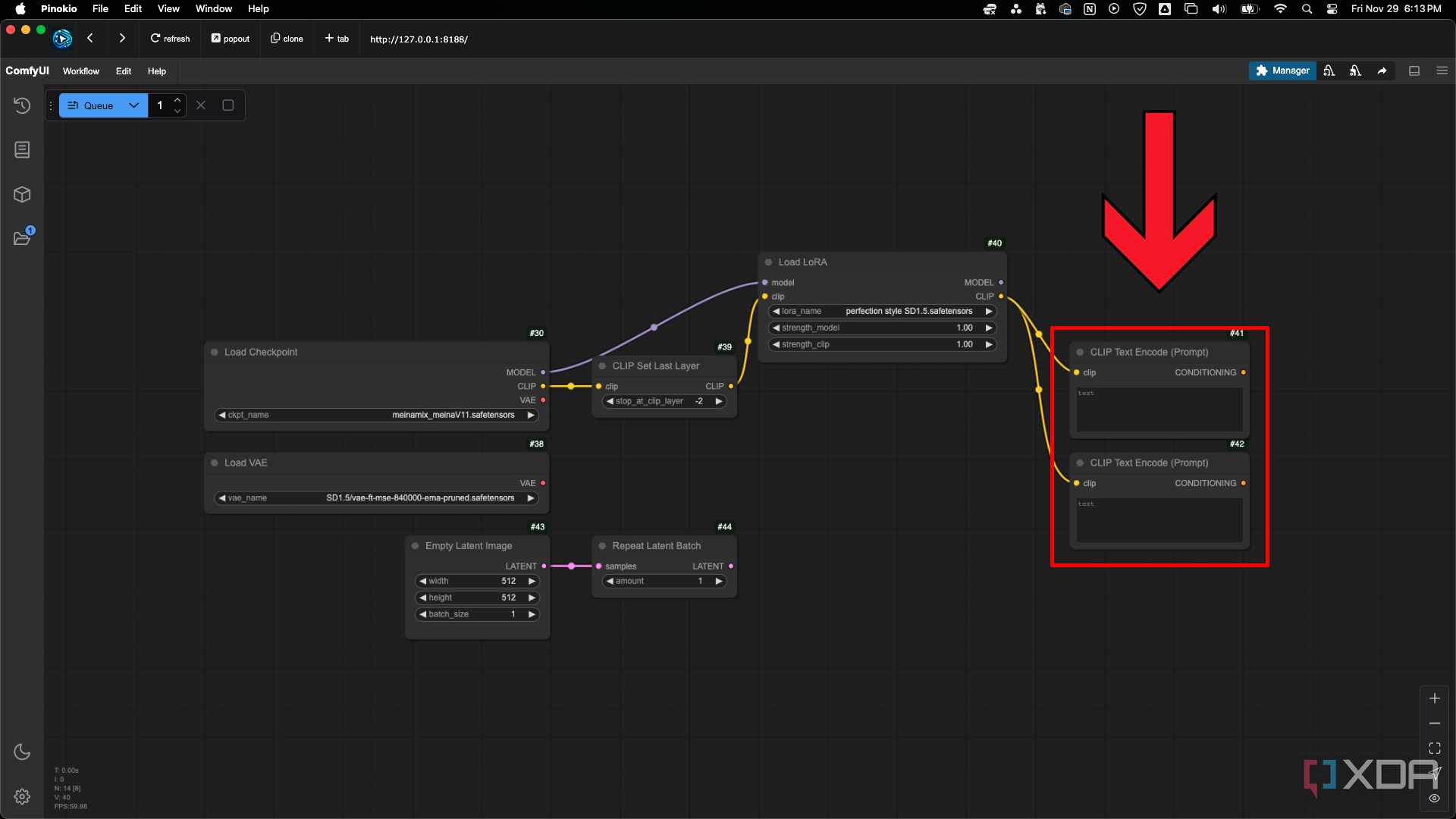
Nodo y conexiones de KSampler
Agregue unnodo KSamplery conecte lassalidas de CONDICIONAMIENTOa lasentradaspositivasy negativas , junto con las conexiones demodeloeimagen latente. Se puede pensar en KSampler como un tipo de procesador especializado. Procesa la información del modelo de punto de control, las LoRA y sus indicaciones para generar una imagen.
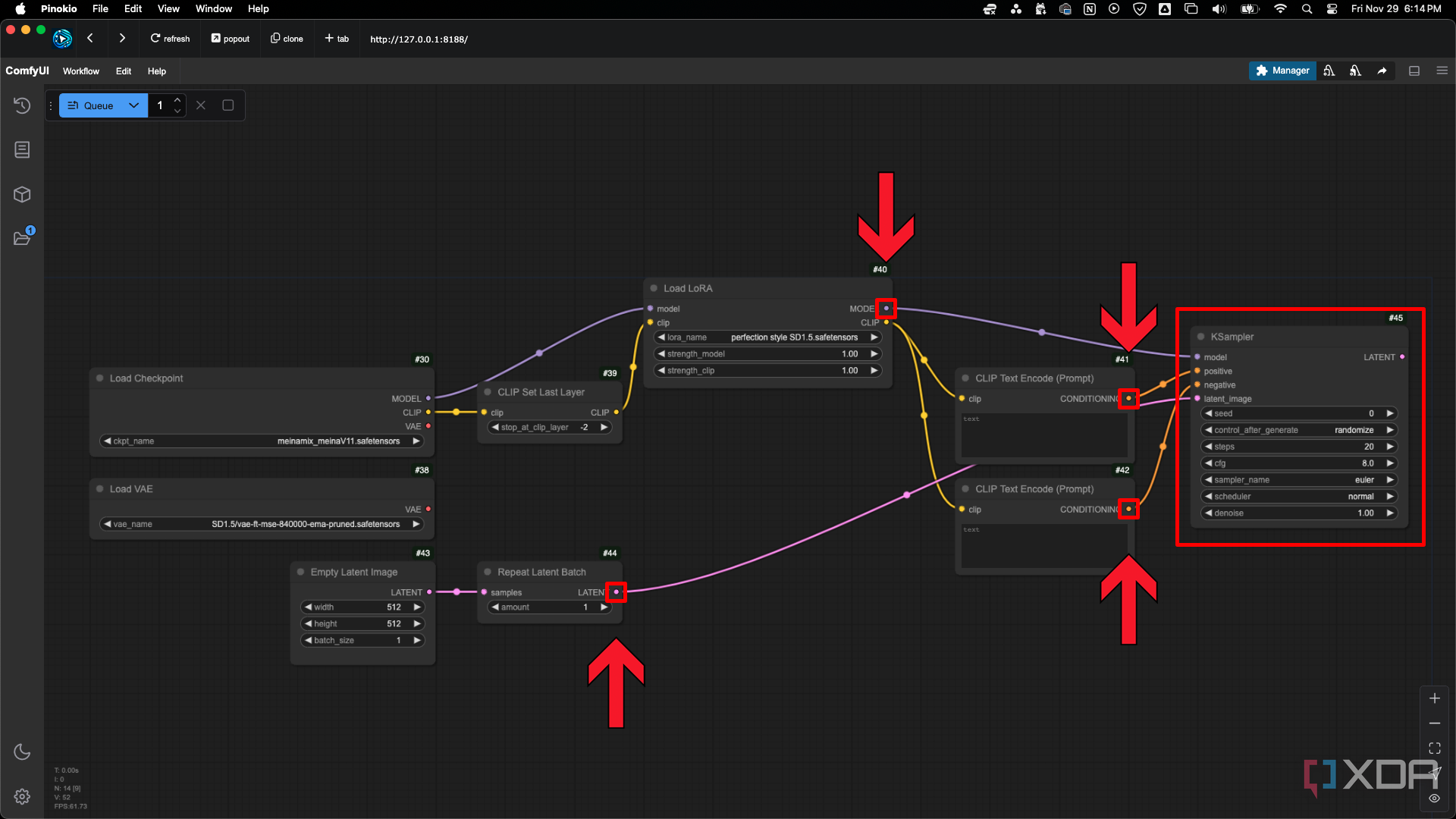
El KSampler tiene varios parámetros clave. El parámetroseedgenera ruido aleatorio para llenar la imagen latente vacía. Cada seed es única, lo que le permite recrear imágenes idénticas utilizando el mismo seed y la misma configuración. El parámetrocontrol_after_generatedetermina cómo cambia el seed o si permanece fijo después de cada generación. El parámetrostepsdetermina cuántos pasos se necesitan para refinar el ruido y convertirlo en una imagen coherente. Los pasos más altos brindan más detalles, pero requieren más tiempo. El parámetrocfgajusta la firmeza con la que el modelo se adhiere a las indicaciones de texto, lo que equilibra la creatividad y el control.
Un número más bajo permite que el modelo sea más "creativo" en lo que produce, mientras que un número más alto le da a sus indicaciones más control sobre lo que se produce. Los números más altos pueden comenzar a producir artefactos, distorsiones e imágenes duras que están sobresaturadas y tienen un alto contraste. El rango de configuración viable puede tener una correlación con la fuerza del modelo LoRA, por lo que es posible que pueda reducir la fuerza LoRA para aumentar aún más la configuración.
SUGERENCIA: Establezca un número de pasos bajo para generar imágenes más rápido. Cuando vea una imagen que crea que tiene potencial o una composición que le guste, corrija el valor inicial y aumente el número de pasos.
Muestreadores y programadores en el nodo KSampler
Sampler_nameyschedulerpueden parecer abrumadores con la cantidad de opciones. Elsampleres la herramienta y el método que se utiliza para eliminar el ruido de la imagen. De forma muy simplificada, se puede pensar en él como si fueran pinceladas. Algunas técnicas de pintura son rápidas y toscas, y otras son lentas y precisas.Los schedulersdeterminan el plan general para eliminar el ruido, indicando al sampler cuándo eliminar el ruido y cuánto ruido eliminar en cada paso.
No todos los muestreadores y programadores funcionan juntos, y tampoco todos funcionan bien para diferentes modelos de puntos de control. Te sugiero que no dediques demasiado tiempo a cambiarlos, a menos que tu hardware sea capaz de generar imágenes muy rápidamente. Consulta la descripción del modelo de punto de control o las imágenes que se han generado utilizando ese modelo en Civitai para ver los muestreadores que funcionan con ese modelo.
Probablemente te interese más jugar con LoRAs y avisos. Mi sugerencia es que te quedes con algunas combinaciones de sampler y scheduler que se usan con frecuencia y que normalmente funcionan con la mayoría de los modelos. Euler y euler_ancestral funcionan bien con los schedulers normal, karras y exponencial. Los samplers dpmpp_2m_sde y dpmpp_3m_sde se usan con frecuencia con el scheduler karras. DDIM y ddim_uniform a veces pueden funcionar bien para imágenes fotorrealistas. A menos que se sugiera lo contrario en Civitai, quédate con ellos hasta que sientas que tienes un buen conocimiento de los avisos y el uso de LoRAs.
Nodos de decodificación VAE, selector de vista previa y guardar imagen
Utilice el nodoVAE Decodepara convertir la imagen latente en una imagen que pueda ver. Utilice el nodoPreview Chooserpara revisar la imagen y pásela al nodoSave Imagesi desea conservarla. Este flujo de trabajo básico proporciona una comprensión clara de cada paso del proceso de generación de imágenes.
Vale la pena aprender ComfyUI como herramienta de IA generativa
Los críticos pueden afirmar que la generación de imágenes con IA produce resultados de baja calidad, pero ComfyUI ofrece un control detallado del proceso. Su interfaz basada en nodos puede parecer intimidante al principio, pero aprender los conceptos básicos prepara a los usuarios para solucionar problemas y crear de manera eficaz. Comprender los puntos de control, las imágenes latentes, las indicaciones, los muestreadores y los VAE crea una base sólida que respalda la IA en proyectos creativos.
Los modelos de punto de control contienen información sobre cómo pueden verse las distintas imágenes. Las imágenes latentes son como el lienzo en el que se genera la imagen. Las indicaciones de CLIP determinan el contenido de la imagen con su entrada. KSampler agrega ruido a la latente y luego procesa todo para crear una imagen eliminando un poco de ruido en cada paso. Los modelos VAE convierten imágenes en latentes y latentes en imágenes, por lo que puede trabajar con sus imágenes existentes o ver los resultados después del procesamiento.
La IA puede ser una herramienta útil en tu proceso creativo, incluso si no eres el mejor artista tradicional. La expresión personal se da de muchas formas y todo el mundo debería tener la oportunidad de hacerlo. Los creativos profesionales se beneficiarán de aprender a usar estas herramientas ahora, en lugar de esforzarse por ponerse al día más tarde. Otras herramientas creativas profesionales, como Adobe Photoshop, han estado integrandosu propia IA generativaimpulsada por Firefly, y muchas más empresas centradas en la creatividad seguramente seguirán su ejemplo.

Cómoda interfaz de usuario
Un programa de código abierto basado en nodos que permite a los usuarios generar imágenes, vídeos y audio utilizando modelos de difusión de IA gratuitos y otras herramientas de IA.