

Bit by Bites una columna semanal que se centra en los avances técnicos todas las semanas en varios espacios. Mi nombre es Adam Conway y he estado cubriendo temas tecnológicos y siguiendo las últimas novedades durante una década. Si hay algo que te interesa y te gustaría que se cubra, puedes contactarme en[email protected].
Si alguna vez ha realizado una búsqueda en Google y ha visto un mensaje en la parte inferior de la pantalla que dice algo como "Algunos resultados pueden haber sido eliminados en virtud de la ley de protección de datos", entonces habrá experimentado de primera mano el derecho al olvido. Se trata de una filosofía que sugiere que los particulares deberían poder eliminar información sobre sí mismos de los motores de búsqueda y otros sitios. En la actualidad, se trata de un derecho principalmente de la Unión Europea, pero muchos países fuera de la UE también tienen sus propias normas al respecto, y Google ha ampliado el derecho a solicitar la eliminación de datos a los ciudadanos estadounidenses.
Sin embargo, existe un dilema interesante en lo que respecta al derecho al olvido y cómo se relaciona con un modelo de lenguaje amplio comoChatGPT. No está claro si realmente se aplica, pero un descubrimiento reciente con ChatGPT sugiere que OpenAI está intentando encontrar formas de respetar esos derechos en caso de que la empresa se veaobligadaposteriormente a cumplir esas solicitudes. Si ese es el caso, la empresa podría encontrarse entrando en un territorio muy peligroso en el futuro.
Los LLM como ChatGPT no pueden "pensar" y debemos dejar de pretender que pueden
La gente habla de LLM y de razonamiento, pero la verdad es que los LLM no pueden pensar y solo operan con base en patrones.
¿Qué pasó?
"David Mayer" pasó
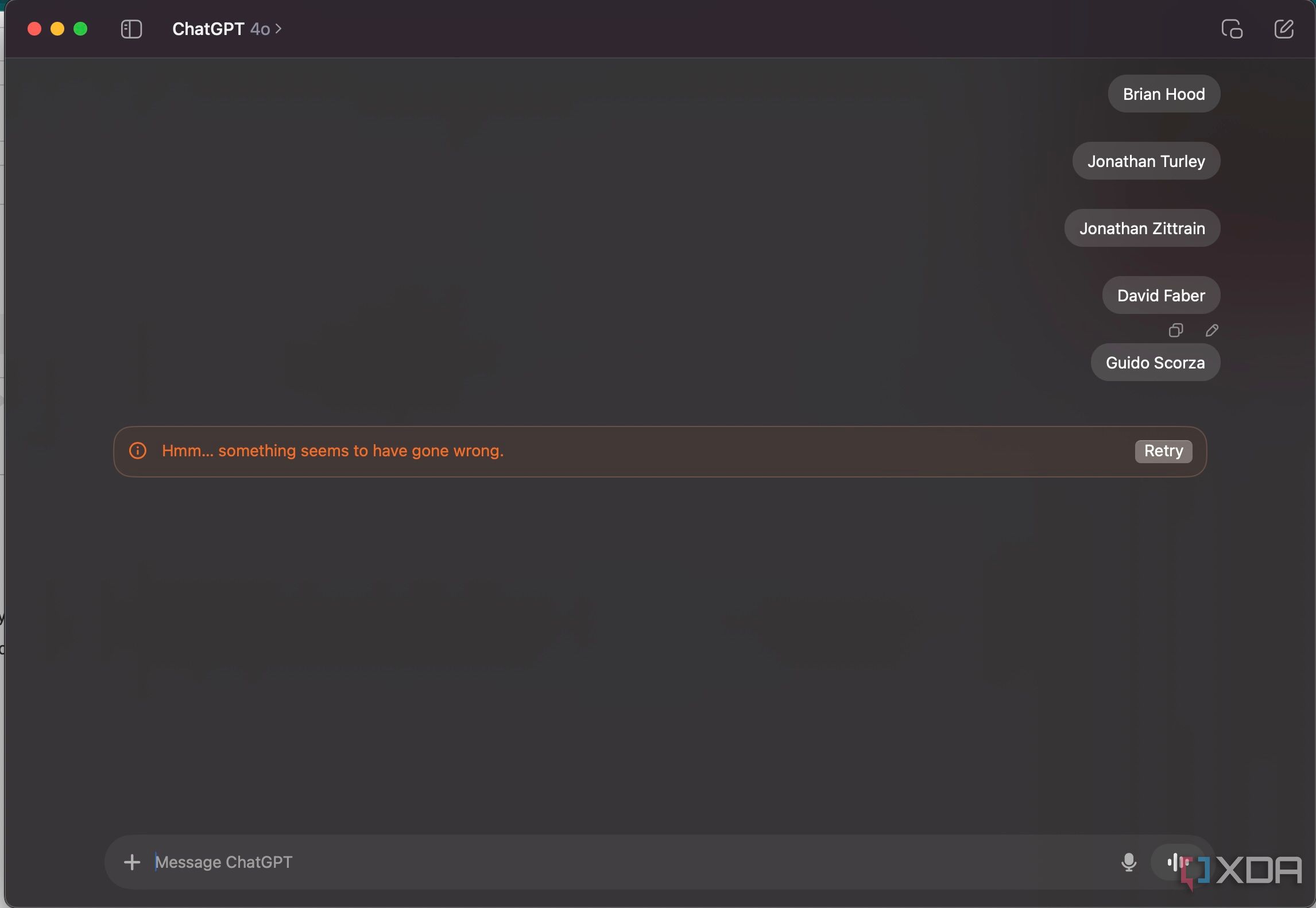
Todo empezó con el nombre "David Meyer", donde los usuarios notaron que ChatGPT se negabadirectamente a responder preguntas sobre el nombre o responder al nombre, y que intentar forzarlo a decir el nombre generaba un error. Después de un tiempo, comenzaron a aparecer otros nombres que enfrentaban el mismo problema, como lo compartióArsTechnica. Estos incluyen, entre otros:
- Brian Capucha
- Jonathan Turley
- Jonathan Zittrain
- David Faber
- Guido Scorza
Más tarde se hizo evidente que todos estos nombres tenían algo en común: se había solicitado que Google eliminara los datos relacionados con ellos. Se corrigió el error "David Mayer" y ahora ChatGPT puede decirlo, pero el resto no.
En cuanto al problema real, OpenAI le dijo aThe Guardiana través de un portavoz que “una de nuestras herramientas marcó por error este nombre y evitó que apareciera en las respuestas, lo que no debería haber sucedido. Estamos trabajando para solucionarlo”. Si bien es una declaración bastante inocua, leer entre líneas sugiere que OpenAI filtra algunos nombres de las respuestas y que David Mayer fue filtrado por error.
¿Puede funcionar el derecho al olvido cuando se trata de un LLM?
¿Y puede causar también otros problemas?
Los LLM se entrenan con una gran cantidad de datos, y estos no se almacenan en una base de datos donde se pueda recuperar información específica. Eliminar datos de forma retroactiva es prácticamente imposible, y rastrear los datos hasta los parámetros con los que se entrenaron es una tarea increíblemente difícil. Además, identificar datos personales en esos conjuntos de datos es increíblemente difícil, especialmente si alguien tiene el mismo nombre que otra persona.
Como resultado, la táctica que ha adoptado OpenAI consiste en filtrar las respuestas, en esencia, envolviendo las respuestas del LLM dentro de un software que las analiza en busca de contenido que debería filtrarse. Así es como OpenAI evita las respuestas que contienen contenido problemático, y lo mismo ocurre con la prevención del entrenamiento del LLM con datos problemáticos. Esto es también lo que permite los"jailbreaks" de ChatGPTque evitan estas condiciones.
A medida que se añaden más y más nombres al filtro que elimina contenido, pueden surgir más problemas. ¿Cómo se puede dar cuenta de cada persona que quiere que se eliminen sus datos y cómo se puede controlar eso? Debido a la naturaleza sensible de la eliminación de datos, es probable que ChatGPT rechace la solicitud al instante en lugar de intentar filtrarla para evitar cualquier posibilidad de que se comparta información personal con el usuario. Es muy probable que ChatGPT tenga dificultades con grandes franjas de Internet si intentara respetar todas las solicitudes de eliminación.
Por ejemplo, es probable que "Brian Hood", alcalde del condado de Hepburn, sea uno de los nombres que amenazó con demandar a OpenAI por las declaraciones difamatorias que hizo sobre él. Le dio a OpenAI 28 días para filtrar su nombre de las declaraciones difamatorias, lo que la empresa aceptó hacer. Desde entonces, su nombre ha provocado que ChatGPT falle cuando lo escribes en una solicitud, al igual que los otros nombres.
Curiosamente, "Jonathan Zittrain" dijo a404 Mediaque, a pesar de señalar los problemas en torno a la IA en un artículo de opinión publicado enThe Atlantic, no sabe por qué ChatGPT filtra su nombre en el servicio. Al buscar su nombre en Google, también se revela que se ha eliminado contenido en virtud de las leyes de protección de datos, lo que supongo que está relacionado. Sin embargo, esto no se puede probar.
En cuanto a "Jonathan Turley", escribió en una publicación de blog que ChatGPT lo difamó, pero le dijo a404 Mediaque no presentó ninguna demanda contra OpenAI ni que OpenAI se puso en contacto con él. Sin embargo, su nombre también genera un error y, al buscar su nombre, aparece la misma bandera que Zittrain, que dice que se eliminó contenido en virtud de las leyes de protección de datos.
5 maneras en las que ChatGPT me hace la vida más fácil
ChatGPT todavía no ha llegado a la etapa de cambio de vida que la gente pensaba que llegaría, pero me ayuda en mi vida diaria.
¿Cómo se ve el futuro de la IA?
Es difícil decir quién gana al final.
Ahora que los legisladores están tomando medidas enérgicas contra la IA y la forma en que esta puede procesar los datos de los usuarios, es probable que este problema se vuelva cada vez más generalizado con el paso del tiempo. Si se impone el derecho al olvido a los creadores de LLM como OpenAI, es probable que el cambio deba provenir de los datos de entrenamiento en lugar de los filtros que rodean al producto terminado. Pero, ¿qué pasa con las páginas web públicas que contienen información? ¿Los LLM ya no pueden interactuar con ellas?
Esta será tanto unacuestión éticacomo técnica, y cualquier enfoque que adopten las empresas tendrá desventajas significativas, ya sea para las personas que solicitaron que se eliminaran sus datos o para las empresas que tengan que eliminar esos datos.