

El almacenamiento en la nube se ha convertido en un término un tanto nebuloso en la actualidad. Es posible que al principio pienses en el almacenamiento en la nube comoGoogle Driveo OneDrive, pero es mucho más amplio. La mayoría de los sitios web probablemente se atienden, al menos en parte, mediante algún tipo de almacenamiento en la nube; ya sea en S3 de AWS, ejecutándose en un servidor web básico en algún lugar que sirva un archivo estático, o alojado directamente en una plataforma como Google Drive. Sin embargo, todas estas soluciones tienen algo en común: no almacenan datos "en" Internet, sino que los almacenan "en" Internet, ubicados endirecciones de servidoresque contienen la información y, en teoría, podrían desaparecer de Internet en cualquier momento. Entonces, ¿sería posible almacenar datos "en" Internet, de forma gratuita?
Se almacenan más datos durante el vuelo de lo que se cree
Quizás le sorprenda saber que esto ya se ha sugerido y se ha hecho antes. El almacenamiento de datos en tránsito no es un fenómeno nuevo. Al almacenar datos en tránsito, es decir, mientras se transmiten de un sistema a otro, evita que los sistemas tengan que almacenar todos los datos a la vez, lo que reduce los costos de almacenamiento en el proceso. En realidad, esta no es una idea poco común. Las colas de mensajes como Apache Kafka o RabbitMQ, tecnologías comunes en la arquitectura de software, proporcionan sistemas grandes y altamente escalables que permiten enviar mensajes a través de sistemas distribuidos. Por lo general, si bien existe algún elemento de almacenamiento de datos persistente, estos sistemas están diseñados teniendo en cuenta el procesamiento en tiempo real y tienen una funcionalidad mínima para el almacenamiento persistente.

5 razones por las que no necesitas una red de 10 GbE en tu oficina doméstica
Hay algunas razones por las que podría querer una red de 10 GbE, pero para la mayoría de los usuarios domésticos, es mejor invertir su dinero en otra cosa.
Los sistemas de alto rendimiento y en tiempo real también son similares, con ejemplos en el mundo del comercio de alta frecuencia, el procesamiento de datos en tiempo real y las redes de distribución de contenido. Muchos de estos sistemas intercambian un elemento de persistencia por rendimiento, pero dependen de que no todos (o ninguno) de sus datos se guarden en algún tipo de almacenamiento persistente. Al hacer esto, pueden ayudar a evitar los cuellos de botella que pueden encontrar elementos como las bases de datos, las condiciones de carrera, los bloqueos de escritura y la lucha por mantener la coherencia mientras se enfrenta a un cuello de botella físico, es decir, un único sistema de archivos.
¿Cómo podemos probar esto?

Hay un par de formas de probar esto, pero podría decirse que la más genial es usar ICMP. ICMP (o Internet Control Message Protocol, pero mejor conocido comoping) es un protocolo diseñado para determinar si se puede establecer la conectividad entre dos hosts y se utiliza principalmente para diagnosticar problemas de red. Un "ping" es un pequeño mensaje que se envía a otro host para confirmar su disponibilidad, y el segundo host envía una pequeña respuesta.
Aquí es donde comienza la magia: ICMP admite una carga de datos, que se devuelve al host original en la respuesta ICMP. Esta respuesta tarda un tiempo, de ahí el uso coloquial de "ping" para la latencia, especialmente entre los jugadores. Durante este tiempo, sus datos no se almacenan en su sistema de archivos directamente, sino "en Internet" a medida que viajan de un host a otro y luego de regreso. Si hace esto con muchos hosts y muchos, muchos paquetes de ping, es posible generar una cantidad de almacenamiento de datos extremadamente inconsistente en Internet.
Lo que está sucediendo en realidad aquí es una solicitud de eco ICMP (una forma de solicitud en el protocolo ICMP) y una respuesta de eco ICMP. Esta solicitud consiste básicamente en que un dispositivo le pregunta a otro "¿Estás ahí?" y el otro dispositivo responde. A continuación, se recibe una respuesta de eco ICMP que incluye la carga de datos original de la solicitud original.
Cuando decimos "en Internet", lo que realmente queremos decir es en los buffers de varios dispositivos de red en Internet. Este "incremento del buffer" es un costo para los proveedores, ISP y servidores, por lo que existe un aspecto antisocial al utilizar esta idea en cualquier dispositivo que no controlemos.
Es posible que sus datos no vuelvan intactos
Obviamente, esto tiene algunos problemas. El protocolo ICMP se basa en el protocolo UDP (User Datagram Protocol), lo que significa que no hay garantías sobre la integridad de los datos. Además, un único paquete ICMP solo puede almacenar unos 1500 bytes en su carga de datos, lo que significa que para generar un gigabyte de almacenamiento en la nube, necesitarías mantener unas 715 000 conexiones abiertas en cualquier momento. Esto es casi imposible: tu PC, tuenrutadory tu hardware de conmutación se colapsarán mucho antes de que puedas gestionar tantas conexiones abiertas, y eso suponiendo que hayas evitado que tu ISP te limite y hayas encontrado suficientes servidores únicos que respondan a los pings (probablemente la parte más fácil).
Como ICMP depende de UDP, no hay garantía de que vuelvas a ver esos datos, por ejemplo, si bloqueas tu red o la limitas, dejándola perdida en el éter. Por lo tanto, descubrirás rápidamente que cualquier implementación de este tipo de sistema destruirá tus datos, y rápido.
Los tiempos de ping altos serán de ayuda
Sin embargo, este sistema de almacenamiento de datos tiene una peculiaridad extraña. La cantidad de datos que se pueden almacenar en la "nube" en un momento dado depende en gran medida de algunas cosas: en primer lugar, cuántas conexiones abiertas se pueden mantener y cuánto tarda cada conexión en volver. Podemos entender que debe haber una cierta proporción de datos que se encuentran actualmente en el PC, que se han recibido y esperan ser transmitidos, en comparación con los que se encuentran actualmente en tránsito. Al minimizar la cantidad de datos en el PC en un momento dado, ya sea manejando la retransmisión más rápido o aumentando la cantidad de tiempo que los datos pasan en el aire, aumentamos la proporción de almacenamiento "en vuelo" efectivo y ayudamos a reducir la carga en nuestra máquina original.
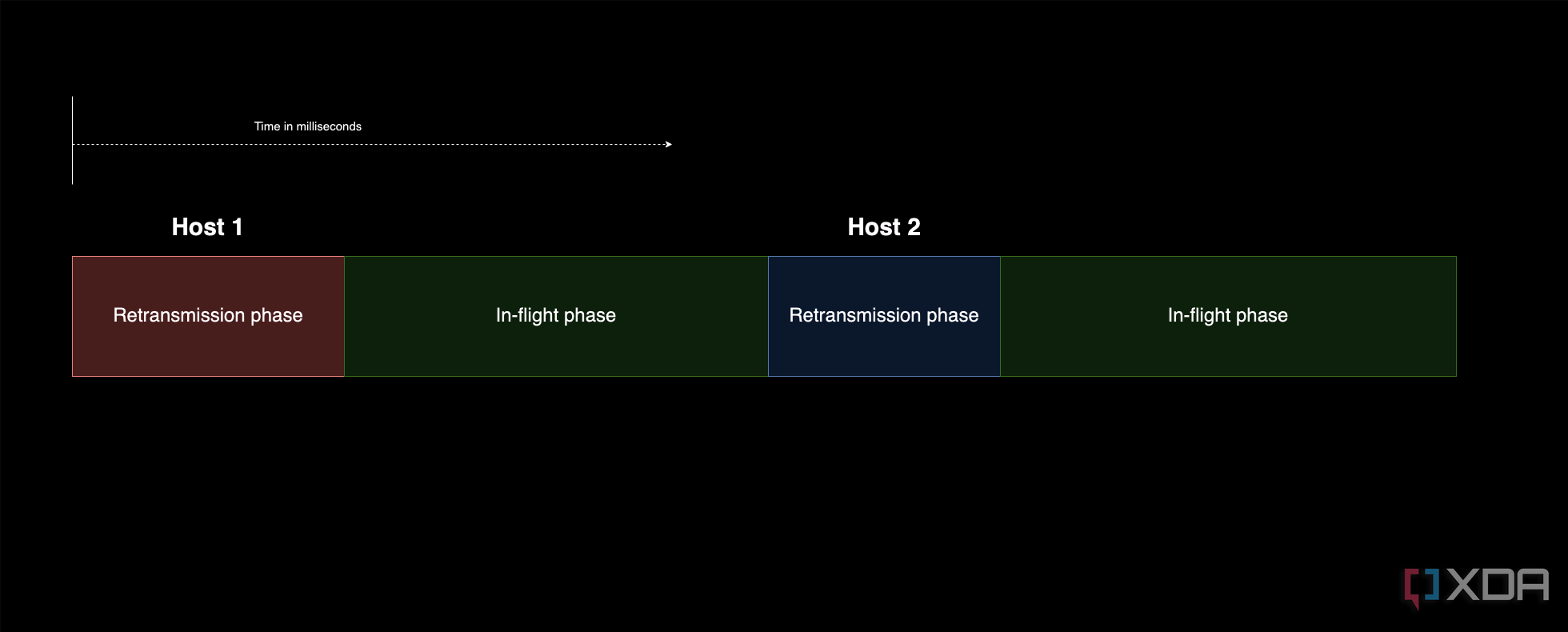
Frente a un menor tiempo de vuelo:
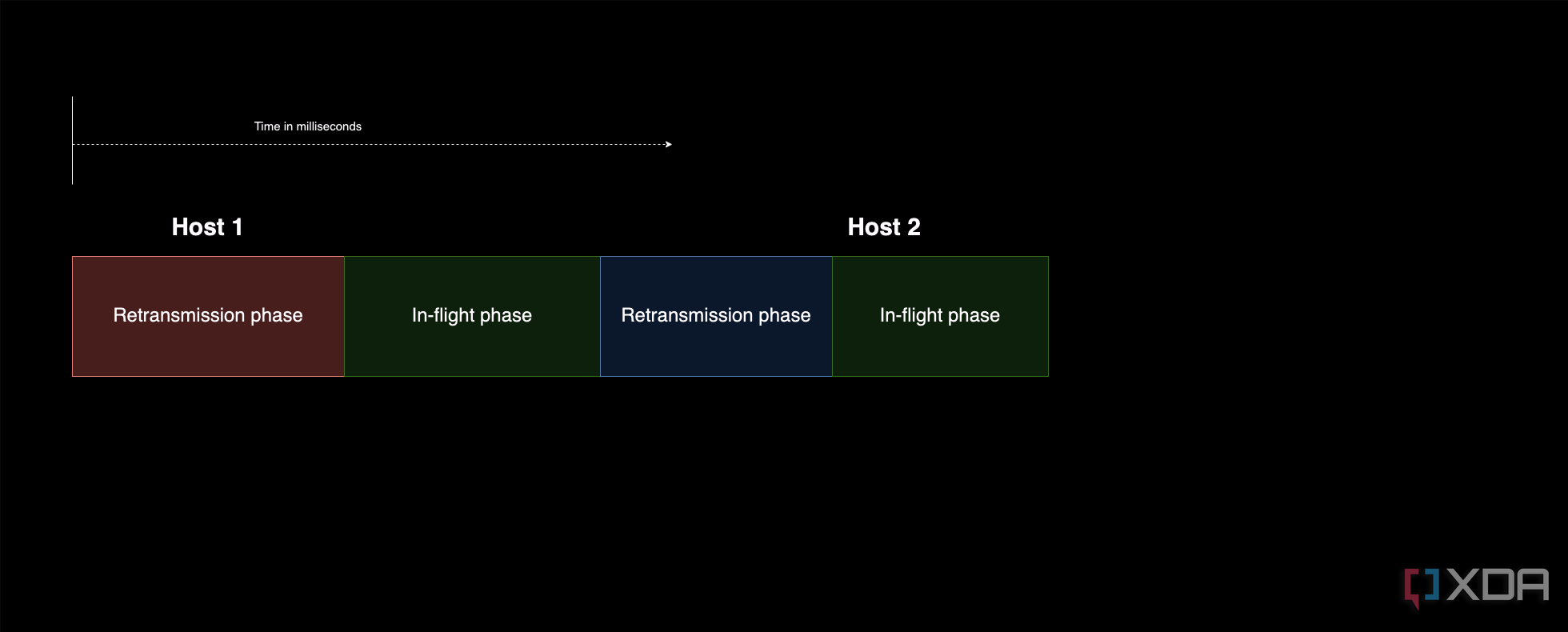
De esta manera, el mejor conjunto de servidores para enviar sus solicitudes de ping con los tiempos de respuesta más largos posibles sería ideal, ya que le permitirá almacenar más datos en vuelo y reducir la carga en su red.
¿Alguien ha implementado esto realmente?
Esta idea ha existido durante un tiempo y existe una implementación funcional.PingFSes una implementación basada en Linux para un sistema de archivos completo que se basa en esta idea. Sin embargo, ponerlo en funcionamiento y compilarlo resultó difícil, por lo que no pude probarlo por completo. Sin embargo, es bastante trivial validar el concepto en Python y he escrito un ejemplo con el que es un poco más fácil jugar y que está disponible enGitHub. Esto demuestra la capacidad de los paquetes ICMP Echo y Reply para almacenar datos, con el script reproduciendo la cadena original de la respuesta recibida. Sin embargo, hacer esto a escala de un sistema de archivos es una tarea mucho más compleja y, si bien es divertido jugar con él, este ejemplo básicamente demuestra lo que ya podemos esperar que suceda dentro del estándar ICMP.
Una cosa es segura: si haces esto, perderás muchos datos. Incluso un intento básico de ejecutar el script anterior para administrar fragmentos de datos de una fuente de datos grande hizo que mi computadora portátil y mi LAN quedaran rápidamente de rodillas.
Un concepto interesante, aunque muy poco práctico
Si bien existen sistemas a nuestro alrededor que almacenan datos de manera efectiva durante la transmisión, o al menos en un formato transitorio mientras se transmiten, esta es una forma bastante terrible de almacenar sus datos. No solo es sumamente antisocial en Internet en general, al descargar sus necesidades de almacenamiento de datos en los búferes y la memoria de los sistemas administrados por otros usuarios y su ISP, sino que también tiene un rendimiento increíblemente alto, ya que requiere una cantidad masiva de conmutación y procesamiento de paquetes por bit de datos (sin mencionar que satura su computadora portátil).
Sin embargo, es un concepto interesante para descargar el almacenamiento de su máquina y una buena manera de entender un poco más cómo funciona Internet. Considere brevemente el volumen de datos "en tránsito" en un momento dado. No se me ocurre una buena manera de calcularlo, pero sospecho que es una cifra muy grande.