

Resumen
- Llama 3 podría debutar pronto con mejoras como una ventana de contexto más grande para competir con los principales competidores de IA como Gemini.
- Considerando el sistema MoE de Mixtral, Llama 3 podría adoptar un enfoque similar para optimizar la eficiencia computacional.
- Se espera que el soporte multilingüe y la multimodalidad sean mejoras para Llama 3 para atender a una base de usuarios más amplia de manera más efectiva.
La carrera por la inteligencia artificial se ha ido calentando poco a poco desde su inicio con ChatGPT. Hemos visto a Bard de Google convertirse en Gemini, a Bing Chat de Microsoft convertirse en Copilot y hemos visto a Meta lanzar su modelo de código abierto Llama 2 que cualquiera puede ejecutar en su propia computadora. Ahora, a medida que avanza la competencia, se espera que Meta lance Llama 3 a finales de este año, posiblementetan pronto como en juliosegún los informes.
Dicho esto, hay una serie de mejoras que nos encantaría ver en Llama 3 cuando se lance para que pueda estar a la altura de la competencia. Estas son algunas de las características y mejoras que más deseamos.
1Ventana de contexto más grande
Parte de lo que hace que Géminis sea tan poderoso
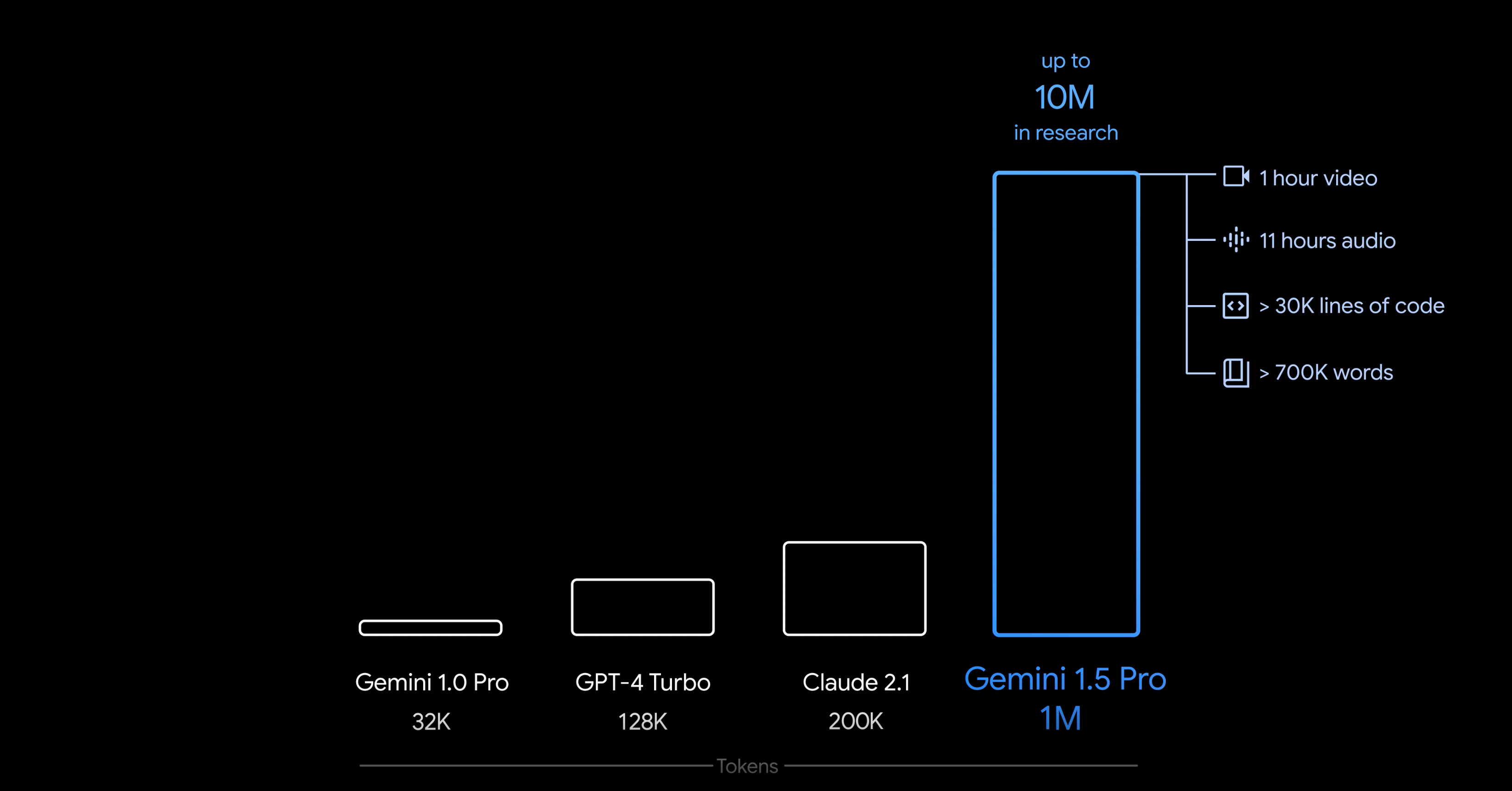
Una ventana de contexto es esencialmente cuánto puede "ver" un LLM en un momento dado, y parte de lo que hace que Gemini sea tan poderoso es su capacidad de tener una ventana de contexto de hasta 10 millones de tokens. Si bien la cantidad de memoria requerida para eso es absurda, una ventana de contexto más grande aún sería increíble. Segúnla tarjeta de modelode LlaMa 2 , actualmente tiene una ventana de contexto de solo 4K tokens, incluso en su modelo de parámetros de 70B. Eso no es mucho contexto y coloca a LlaMa 2 en una posición muy rezagada en comparación con lo que hay actualmente.
Como ya se mencionó, aquí hay limitaciones de memoria, pero hay avances en esta área que pueden hacer que Meta pueda al menosaumentarla ventana de contexto, incluso si no estará cerca del límite de 32K de GPT-4.

Gemini 1.5 Ultra de Google tendrá que competir con GPT-5, no con GPT-4
El modelo Gemini 1.5 Pro de Google nos sorprendió, y el modelo Ultra podría ser aún mejor.
2Mezcla de expertos
Cómo Mixtral consigue competir con GPT-3.5
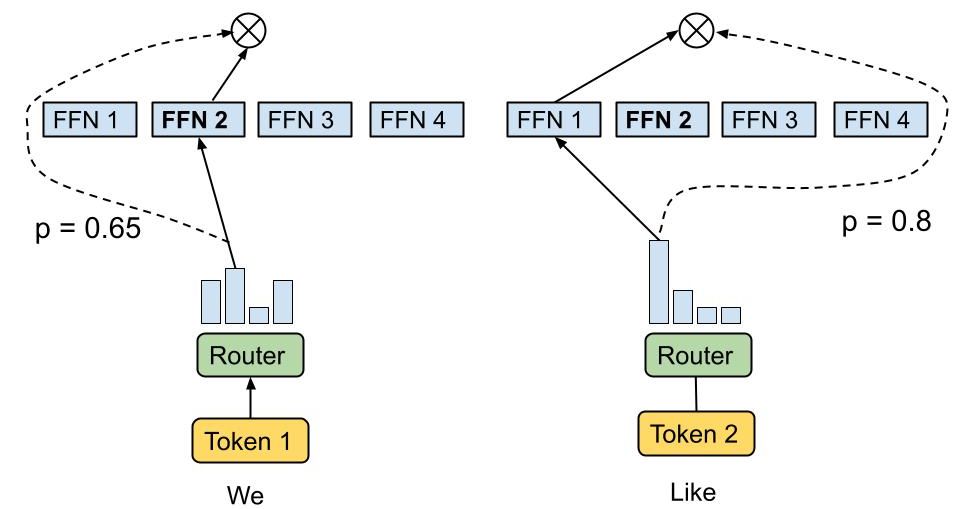
Meta podría aprender de Mixtral 8x7B, un modelo creado por Mistral AI que logra competir con GPT-3.5 y puede ejecutarse localmente en las máquinas de las personas. El modelo Mixtral 8x7B completo requiere un hardware increíblemente potente para ejecutarse, pero también lo requiere LlaMa 2 70B.
Mixtral emplea una arquitectura MoE para procesar los tokens entrantes y los dirige a redes neuronales especializadas dentro del sistema en función de su relevancia. El modelo Mixtral 8x7B cuenta con ocho expertos de este tipo. Cabe destacar que es posible estructurar estos expertos de manera jerárquica, donde un experto puede ser otro MoE. Al recibir una solicitud, Mixtral 8x7B utiliza una red de enrutamiento para determinar el experto más adecuado para cada token. En esta configuración, cada token es evaluado por dos expertos y la respuesta final es una combinación de sus resultados.
El enfoque MoE ofrece varios beneficios, particularmente en términos de eficiencia computacional durante la fase de entrenamiento inicial, aunque puede ser propenso a un sobreajuste durante la etapa de ajuste fino. El sobreajuste ocurre cuando un modelo se familiariza demasiado con sus datos de entrenamiento, lo que lleva a una tendencia a reproducirlos exactamente en sus respuestas. Otra ventaja de los MoE es su potencial para tiempos de inferencia más rápidos, ya que activan solo un subconjunto de expertos para cada consulta. Sin embargo, acomodar un modelo como Mixtral, con sus 47 mil millones de parámetros, requiere una memoria RAM sustancial. El recuento total de parámetros del modelo es de 47 mil millones en lugar de 56 mil millones porque comparte muchos parámetros entre todos los expertos y no simplemente multiplica los siete mil millones de parámetros de cada experto por ocho.
Con este enfoque, LlaMa 3 podría incluso utilizar un MoE en modelos más pequeños, mejorando el tiempo de inferencia y disminuyendo la RAM necesaria. Seguirá siendo necesaria una PC potente, pero nada inalcanzable.

Las mejores GPU en 2025: nuestras mejores tarjetas gráficas
Elegir la tarjeta gráfica adecuada puede resultar difícil dada la gran cantidad de opciones que hay en el mercado. Estas son las mejores tarjetas gráficas que debes tener en cuenta.
3Soporte multilingüe
Cualquier idioma que no sea inglés está actualmente "fuera de alcance".

Según la tarjeta modelo de LlaMa 2, cualquier uso que no sea en inglés queda fuera del alcance. Si bien la mayoría de los LLM se entrenan con datos predominantemente en inglés, a los usuarios internacionales también les gustaría conversar con un LLM en su propio idioma. Servicios como ChatGPT, Google Gemini e incluso Mixtral admiten varios idiomas, pero Meta no lo tiene en cuenta en absoluto con LlaMa 2.
Idioma | Por ciento | Idioma | Por ciento |
Inglés | 89,70% | ucranio | 0,07% |
Desconocido | 8,38% | coreano | 0,06% |
Alemán | 0,17% | catalán | 0,04% |
Francés | 0,16% | serbio | 0,04% |
sueco | 0,15% | indonesio | 0,03% |
Chino simplificado | 0,13% | checo | 0,03% |
Español | 0,13% | finlandés | 0,03% |
ruso | 0,13% | húngaro | 0,03% |
Holandés | 0,12% | noruego | 0,03% |
italiano | 0,11% | rumano | 0,03% |
japonés | 0,10% | búlgaro | 0,02% |
Polaco | 0,09% | danés | 0,02% |
Portugués | 0,09% | esloveno | 0,01% |
vietnamita | 0,08% | croata | 0,01% |
Como resultado, esto es algo que nos encantaría ver cambiar con Llama 3. La tabla anterior está tomada delartículo de investigación de LlaMa 2, donde "Desconocido" está parcialmente compuesto por datos de programación. En otras palabras, sin embargo, otros idiomas palidecen en comparación con el inglés en este conjunto de datos. La inclusión de otros idiomas ampliaría la cantidad de personas que pueden usar LlaMa, ya que en este momento, no tiene sentido que lo usen quienes no hablan inglés.
4Multimodalidad
Admite otros medios además del texto
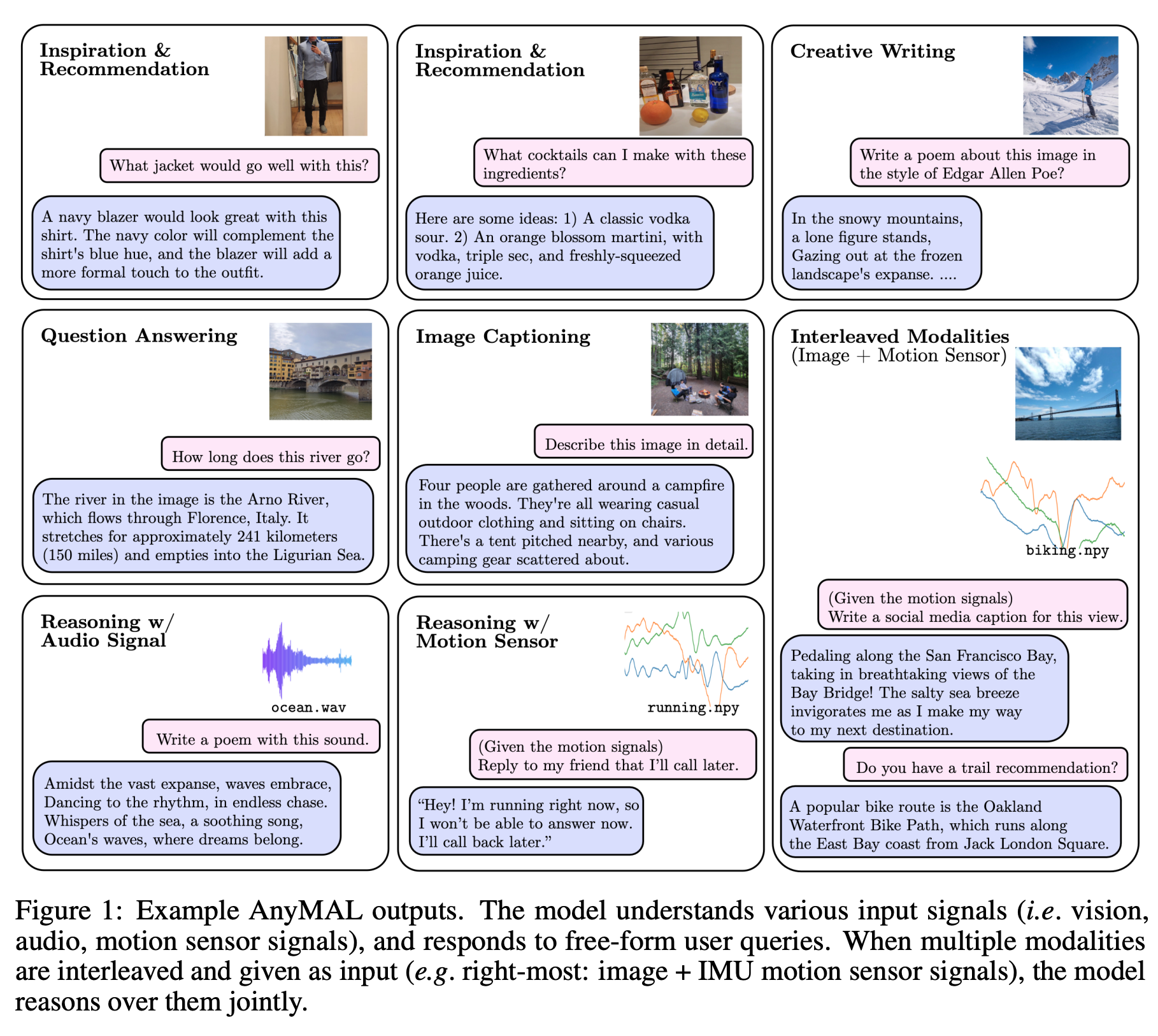
Meta ya ha estado probando modelos de lenguaje que admiten múltiples modalidades, y el equipo de investigación de Metapublicó un artículoque detalla "AnyMAL" en septiembre del año pasado. AnyMAL se describe como "un modelo unificado que razona sobre diversas señales de modalidad de entrada (es decir, texto, imagen, video, audio, sensor de movimiento IMU) y genera respuestas textuales", heredando LlaMa 2. Dado que Meta ya ha trabajado en esto, parece probable que los avances realizados aquí se encuentren en LlaMa 3.
En cuanto a por qué es importante, significa que puedes darle datos a LlaMa 3 en forma de imagen y que te responda con la imagen como contexto. Esto incluye encontrar cosas en imágenes, encontrar problemas con una foto o comprender datos de video y audio. Muchas plataformas están comenzando a admitir esto si aún no lo hacen, y es algo de lo que LlaMa 2 de Meta carece en este momento.
5Una opción de parámetro más intermedia
¿Por qué no 30B?
LlaMa 2 está disponible actualmente en opciones de parámetros 7B, 13B y 70B. Obviamente, hay un salto enorme en los parámetros y sería genial que Meta tomara ejemplo de la competencia y lanzara un modelo que se acercara a los 30B. Sigue siendo un modelo enorme, pero significa que los entusiastas con sistemas modestos aún pueden participar de la diversión con modelos más grandes ejecutándose localmente.
En ese sentido, un modelo más pequeño, 1B o 2B, para competir con modelos como Gemini Nano también podría ser divertido. Algo así podría funcionar en prácticamente cualquier cosa, y significa que incluso más personas pueden probar un LLM por primera vez. Dado que parte de la misión de Meta con LlaMa es democratizar los modelos de IA, no hay mejor manera de hacerlo que garantizar que la mayor cantidad posible de personas puedan probarlos.
Es probable que LlaMa 3 esté a la vuelta de la esquina
Esperamos que LlaMa 3 llegue en algún momento del verano, posiblemente en julio segúnThe Information. Dado que el propósito de LlaMa era ser un modelo de código abierto, esperamos que se diga lo mismo de Llama 3 también. Estamos emocionados por su lanzamiento, ya que la competencia en el espacio siempre es algo bueno. ¡Esperemos que Meta lo mejore sustancialmente! Por ahora, puedes probar los otros modelos de LlaMa 2 usando LM Studio.
Ejecute LLM locales con facilidad en Mac y Windows gracias a LM Studio
Si desea ejecutar LLM en su PC o portátil, nunca ha sido más fácil hacerlo gracias al potente y gratuito LM Studio. Aquí le mostramos cómo usarlo